
Harnessing the power of the atom was a historic event in world history. While the use of atomic energy is debatable and the pursuit of clean fusion remains elusive, the fact is splitting the atom was a game changer – unleashing exponentially larger energy potential than ever before possible, as well as the promise of a whole new frontier of innovative possibilities. Cloud technology has brought the same game changing possibilities to data analytics by offering unprecedented on-demand computing power and storage capacity to a wide range of users.
Having access to a dynamic data platform will be essential to keep up with the onslaught of data from old and new sources. The scope of data required to obtain timely, deep insight in today’s housing industry is expanding:
Like the physical universe, the digital universe is large – by 2020 it will contain nearly as many digital bits as there are stars in the universe. It is doubling in size every two years, and by 2020 the digital universe – the data we create and copy annually – will reach 44 zettabytes, or 44 trillion gigabytes. – Digital Universe Study by IDC (https://www.emc.com/leadership/digital-universe/2014iview/executive-summary.htm)
Expanding Real Estate Data Universe
This proliferation of property data generation is fueled by both traditional real estate documents and tax authorities as well as more recent entrants to the scene: Internet of Things (IOT) sources as well as numerous third-party sources, national and local levels of government, environmental and administrative data such as permits and local use rules that contribute to the universe of data that directly or indirectly impacts the U.S. housing market. IOT sources are evolving rapidly and include home automation, utility telemetry, communication device wearables and other web-enabled devices yet to even be considered.
The expanding universe of real estate data sources challenges traditional approaches to how data solutions are developed and supported within an organization. Typical solutions included identification of the required data sets, sourcing the data sets from various flat files, building separate ETL (extract, transform and load) processes for each data set to integrate the source data into a common database from which a solution could then be constructed.
Concurrently with the ETL build, the IT team would have to devise a plan to house the data and expand server resources to accommodate the new workload. This practice works when there are three or four sources to manage and the total size of the data does not require exorbitant hardware acquisition to accommodate the compute or storage requirements.
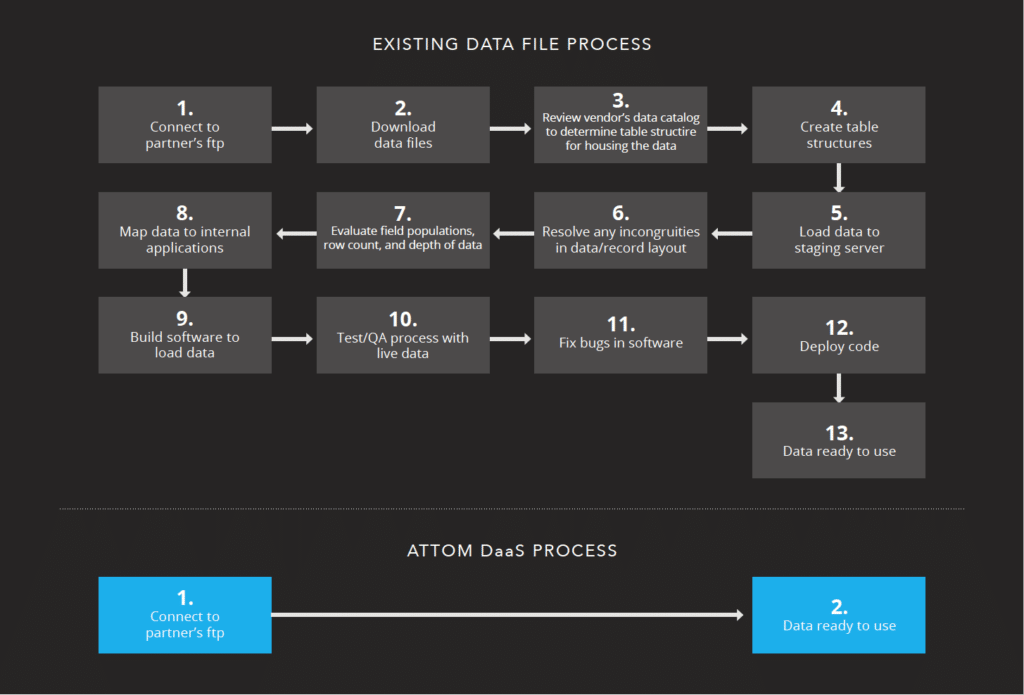
However, what if a research project requires the compilation of years of air quality and property valuation data to evaluate the correlation of air quality levels and home values over time? Granular air quality measurement data and monthly valuation data for each parcel in the United States constitutes well over 15 billion records of data for a 10-year period. Hosting and managing all of that data requires considerable resources for storing, and maintaining — not to mention performing statistical calculation across the data sets. Given a challenge such as air quality and valuation, with only two data sets, it is clear to see that the logistics of assembling and storing large volumes of data can become unwieldy.
Real Estate Data as a Service
To prevent drowning in the tidal wave of data, ATTOM is building a cloud-based data infrastructure that will alleviate the burden of loading, managing and efficiently processing large data sets. ATTOM will take care of the hard parts, allowing our customers to focus on their use cases and understanding how the results of their analysis affect their business.
Removing barriers to using data — this is the key goal in our Data as a Service (DaaS) initiative. Providing a workspace for data discovery and not just delivering data in monolithic flat files that need to be loaded and managed before doing any useful work. The steps a customer has to perform to start using an ATTOM DaaS solution are pretty simple:
On top of upfront costs, storing and managing large quantities of information requires an ongoing investment of time and resources. When you use DaaS, all of the techy “nuts and bolts” are, in theory,
out of sight and out of mind, leaving you free to concentrate on business issues.—Bernard Marr, author of Big Data and Big Data in Practice ( https://www.forbes.com/sites/bernardmarr/2015/04/27/big-data-as-a-service-is-next-big-thing/2/#25818ff470fc)

ATTOM DaaS becomes an extension of the ATTOM Data Warehouse, seamlessly provisioned and updated. Additional data sets can be integrated with unsurpassed ease, efficiency, and sustainability. DaaS effectively eliminates the following challenges in undertaking a data project:
• Too much data to compile at one time in one place
• Too complicated to platform and maintain without additional expertise
• Short-term use of data doesn’t justify investment in the labor required to get started
• Cost prohibitive to platform and or process
Large-scale use cases play well in the DaaS, but small use cases or short-term projects are also easily supported. It has never been easier to get started quickly with a real estate data set that is just the right size for your business.
ATTOM Data believes that the DaaS cloud platform is more than a format change such as VHS to DVD. Rather, it is a paradigm change akin to flat files representing Blockbuster Video rentals and ATTOM DaaS as an on-demand video service experienced on a smart TV. Looking to the future and innovating better solutions is the best way to be relevant when the future arrives at your doorstep.
